本文最后更新于:2020年7月12日 下午
看了优秀的题解,还是把我的辣鸡题解更新一下好了~
一、端午节的淘宝粽子交易
(1)请删除最后一列为缺失值的行,并求所有在杭州发货的商品单价均值。
df = pd.read_csv('端午粽子数据.csv')
df.head()输出:
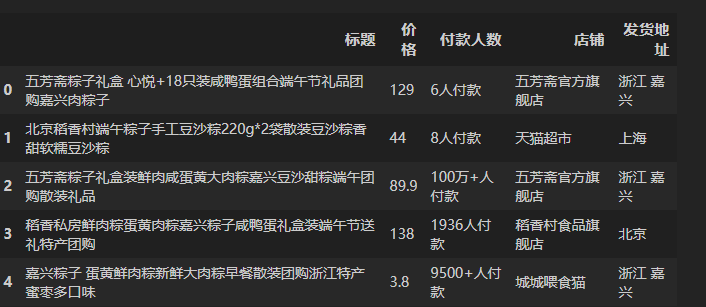
列名中有些包含了空格,先去除。
df.columns = df.columns.str.strip()
df.columns输出:

然后将最后一列为空的行去除,使用dropna方法。再查看最后一列为空的行。
df_clean = df.dropna(axis=0,subset=[df.columns[-1]])
df_clean[df_clean[df_clean.columns[-1]].isna()]输出:

确认已删除完毕。
将所有在杭州交易的记录取出。
df_h = df_clean[df_clean['发货地址'].str.contains('杭州')]查看其中价格列不能转换为float的行。
def is_number(x):
try:
float(x)
return True
except (SyntaxError, ValueError) as e:
return False
df_h[~df_h['价格'].map(is_number)]输出:

将其价格改为45。计算价格转换为float类型并计算均值。
df_h.loc[4376]['价格'] = 45
df_h['价格'].astype('float').mean()
# to_numeric也是ok的~
# pd.to_numeric(df_h['价格']).mean()输出:

(2)商品标题带有”嘉兴”但发货地却不在嘉兴的商品有多少条记录?
直接使用contain方法求取即可。
df_bj = df_clean[df_clean['标题'].str.contains('嘉兴')]
df_bj_nj =df_bj[~(df_bj['发货地址'].str.contains('嘉兴'))]
df_bj_nj.shape输出:
(1032, 5)(3)请按照分位数将价格分为“高、较高、中、较低、低” 5个类别,再将类别结果插入到标题一列之后,最后对类别列进行降序排序。
查看价格列中异常值。
df_clean[~df_clean['价格'].map(is_number)]输出:
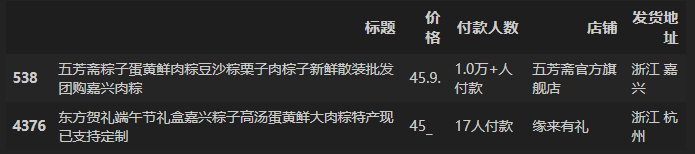
修改为对应的正常值。
df_clean.loc[538]['价格'] = 45.9
df_clean.loc[4376]['价格'] = 45使用qcut方法将价格按数量等分为5类。并重命名为“高、较高、中、较低、低” 5个类别。
q_cut = pd.qcut(df_clean['价格'].astype('float'),5)
df_clean.loc[:,'类别'] = q_cut.cat.rename_categories(['低','较低','中','较高','高'])
# 上面两行可以优化为如下形式,效果一样的~
q_cut = pd.qcut(df_clean['价格'].astype('float'),5, labels=(['低','较低','中','较高','高'])
df_clean.loc[:,'类别'] = q_cut将列顺序按要求排列。并将表格按照类别进行降序排列。
df_clean = df_clean[['标题','类别','价格','付款人数','店铺','发货地址']]
df_clean = df_clean.sort_values('类别', ascending=False)输出:
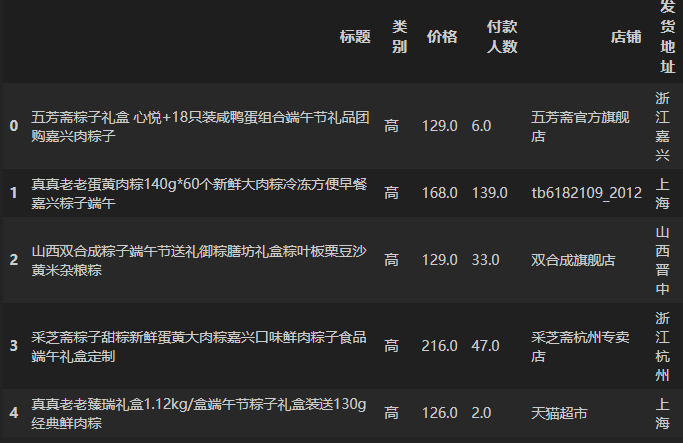
(4)付款人数一栏有缺失值吗?若有则请利用上一问的分类结果对这些缺失值进行合理估计并填充。
查看付款人数一栏有缺失值的行。
df_clean[df_clean['付款人数'].isna()]输出:
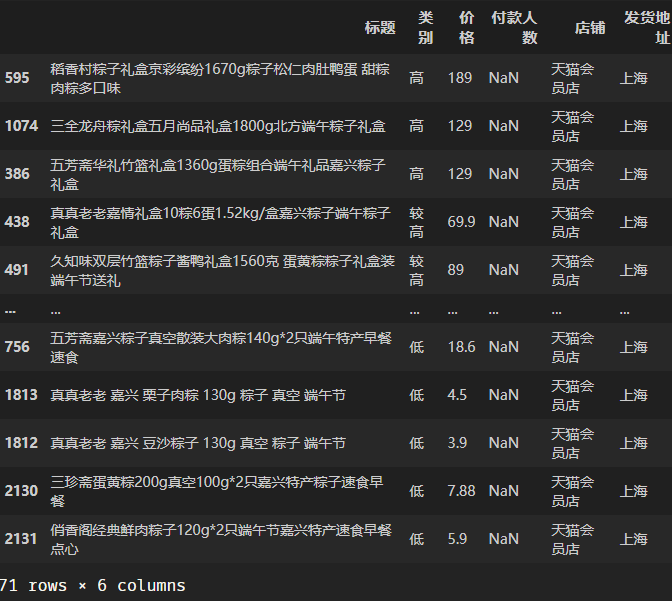
(我想起来了,上次写到这,晚上11点多了,注释一个都不写了,直接粗暴贴代码o_o ….补上补上)
replace函数将付款人数一列的数字提取出来,然后根据付款人数对价格线性插值,这里线性插值需要把付款人数作为index索引。所以下一步就是把列重新排好序。
def replace(x):
try:
x = str(x)
if '万' in x:
i = x.index('万')
return float(x[:i]) * 10000
if '+' in x:
i = x.index('+')
elif '人' in x:
i = x.index('人')
else:
# print(x)
return None
return int(x[:i])
except:
print(x)
return Nonedf_clean['付款人数'] = df_clean['付款人数'].map(replace)
df_clean = df_clean.set_index('价格')
df_clean['付款人数'] = df_clean['付款人数'].interpolate(method='index')
df_clean = df_clean.reset_index()
df_clean = df_clean[['标题','类别','价格','付款人数','店铺','发货地址']](5)请将数据后四列合并为如下格式的Series:商品发货地为xx,店铺为xx,共计xx人付款,单价为xx。
列合并,把列类型转换为str类型,然后相当于对字符串进行合并。
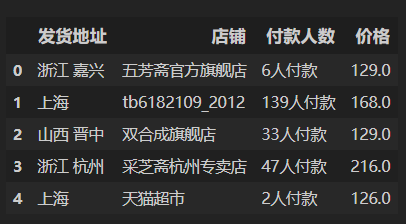
result = '商品发货地为'+df_clean['发货地址']+',店铺为'+df_clean['店铺']+',共计'+df_clean['付款人数'].astype('str')+',单价为'\
+ df_clean['价格'].astype('str')+'元'输出:

# 错误题解
result.str.extract(r'商品发货地为(?P<发货地址>[\w]+),店铺为(?P<店铺>[\w]+) \
,共计(?P<付款人数>[\w]+),单价为(?P<价格>[?\d.\dh]+)元')(做题的时候,提取的时候失败了。。当然看了优秀题解的我又回来了)
new_df = pd.DataFrame(index=df_clean.index)
new_df['发货地址'] = result.str.extract(r'商品发货地为(.+),店')
new_df['店铺'] = result.str.extract(r'店铺为(.+),共')
new_df['付款人数'] = result.str.extract(r'共计(.+),单')
new_df['价格'] = result.str.extract(r'单价为(.+)元')
new_df.head()或者下面这种一步到位。
result.str.extract(r'商品发货地为(?P<发货地址>.+),店铺为(?P<店铺>.+),共计(?P<付款人数>.+),单价为(?P<价格>.+)元')输出:
二、墨尔本每日最低温度
(1) 剔除国庆节、五一劳动节和每月第一个周一,求每月的平均最低气温。
读取墨尔本每日温度数据。
df2 = pd.read_csv('墨尔本温度数据.csv', parse_dates=['Date'])
df2.head() Date Temp
0 1981-01-01 20.7
1 1981-01-02 17.9
2 1981-01-03 18.8
3 1981-01-04 14.6
4 1981-01-05 15.8把Data列转换为时间类型。
df2['Date'] = pd.to_datetime(df2['Date'])把每月第一个周一、国庆节、五一劳动节的时间聚合在一起。按照时间顺序排列。
#d = pd.date_range(start='1981-1-1',end='1990-12-31')
d = df2['Date']
mask1 = (d.dt.weekday==0) & (d.dt.day>0) &(d.dt.day<=7)
mask10 = (d.dt.month == 10) & (0<d.dt.day) & (d.dt.day<=8)
mask5 = (d.dt.month == 5) & (d.dt.day>0) & (d.dt.day<=5)
holidays = d[mask1].append(d[mask5]).append(d[mask10]).sort_values()
# print(holidays)剔除holiday之后,对每月resample求平均值。
result = df2[~df2['Date'].isin(holidays)].set_index('Date').\
resample('MS').mean()
result.head()输出:
Temp
Date
1981-01-01 17.776667
1981-02-01 17.637037
1981-03-01 13.330000
1981-04-01 12.210345
1981-05-01 9.273077(2)季节指数是一种对于周期性变化序列的特征刻画。记数据集中第k年平均最低气温为$TY_k(k=1,…,10)$,第k年第j个平均最低气温为$TY_{kj}(j=1,…,10)$,定义$S_j=\frac{ \sum_{k} TM_{kj} }{ \sum_{k} TY_k }$。请按照如上定义,计算12个月的季节指数$S_j$。
就是把数据按照年Y聚合,求均值再求和得到$\sum_{k} TY_k$。把数据按照月聚合,按照月份求和得到$\sum_{k} TM_{kj}$,两者相除得到$S_j$。
melbourne = df2.set_index('Date')
TY_K = melbourne.resample('Y').mean()
TY = TY_K.sum()
TM_KJ = melbourne.resample('MS').mean()
for i in range(1,13):
result_i = TM_KJ[TM_KJ.index.month==i].sum() / TY
print('S{}='.format(i),result_i.values[0].round(decimals=4))输出:
S1= 1.3447
S2= 1.3758
S3= 1.3031
S4= 1.0815
S5= 0.8827
S6= 0.6511
S7= 0.5987
S8= 0.706
S9= 0.8031
S10= 0.9223
S11= 1.1165
S12= 1.2394(3)移动平均法是一种时间序列的常见平滑方式,可分为k期移动平均和k期中心移动平均,都使用了某一时刻及其周围的数据对该时刻的数据进行平滑修正。设原序列为$x_1,\ldots,x_n$,对于$x_t$的k期移动平均修正$\tilde{x_t}$为$\frac{ \sum_{i=0}^{k-1} x_{t-i}}{k}$,对于k期中心移动平均修正为
(a)求原序列的5期移动平均序列。
这个第一次遇到,很巧妙。就是用rolling方法把window=5的窗口聚合,求和,然后往后移动两位,就是$\sum_{i=0}^{k-1} x_{t-i}$,再除以k就ok啦。
melbourne.rolling(window=5, min_periods=-5).sum().shift(-2)/5
# window和min_periods什么关系?输出:
Temp
Date
1981-01-01 11.48
1981-01-02 14.40
1981-01-03 17.56
1981-01-04 16.58
1981-01-05 16.16
... ...
1990-12-27 13.72
1990-12-28 14.28
1990-12-29 13.96
1990-12-30 NaN
1990-12-31 NaN
[3650 rows x 1 columns](b)求原序列的5期与6期中心移动平均序列。
跟上一题差不多的啦,就不写啦。
(melbourne.shift(-3)/2+melbourne.shift(3)/2+melbourne.rolling(window=5,min_periods=-5).sum().shift(-2))/6输出:
Temp
Date
1981-01-01 57.4
1981-01-02 72.0
1981-01-03 87.8
1981-01-04 82.9
1981-01-05 80.8
... ...
1990-12-27 68.6
1990-12-28 71.4
1990-12-29 69.8
1990-12-30 NaN
1990-12-31 NaN
[3650 rows x 1 columns]三、2016年8月上海市摩拜单车骑行记录
(这题我吐槽我自己,写的太复杂啦。做了前2题半,用group做,是真的写的丑。时间序列那章没学好,统统删掉重写)
(1)平均而言,周末单天用车量比工作日单天用车量更大吗?
(第一题优秀题解有点问题,使用D是单天用车量。)
df3 = pd.read_csv('摩拜单车数据.csv')
df3.head()输出:
orderid bikeid userid start_time start_location_x \
0 78387 158357 10080 2016-08-20 06:57 121.348
1 891333 92776 6605 2016-08-29 19:09 121.508
2 1106623 152045 8876 2016-08-13 16:17 121.383
3 1389484 196259 10648 2016-08-23 21:34 121.484
4 188537 78208 11735 2016-08-16 07:32 121.407
start_location_y end_time end_location_x end_location_y \
0 31.389 2016-08-20 07:04 121.357 31.388
1 31.279 2016-08-29 19:31 121.489 31.271
2 31.254 2016-08-13 16:36 121.405 31.248
3 31.320 2016-08-23 21:43 121.471 31.325
4 31.292 2016-08-16 07:41 121.418 31.288
track
0 121.347,31.392#121.348,31.389#121.349,31.390#1...
1 121.489,31.270#121.489,31.271#121.490,31.270#1...
2 121.381,31.251#121.382,31.251#121.382,31.252#1...
3 121.471,31.325#121.472,31.325#121.473,31.324#1...
4 121.407,31.291#121.407,31.292#121.408,31.291#1...把start_time和end_time(str)转换为时间类型。把start_time设置为index。然后按照工作日和周末计算单天用车量。
df3['start_time'] = pd.to_datetime(df3['start_time'])
df3['end_time'] = pd.to_datetime(df3['end_time'])
df_mobike = df3.set_index('start_time', drop=True)
df_count[df_count.index.dayofweek.isin([5,6])].mean()[0]
df_count[df_count.index.dayofweek.isin([0,1,2,3,4])].mean()[0]输出:
3275.125 # 周末
3311.304347826087 # 工作日显然,平均而言,工作日的单天用车量更大。
(2)工作日每天的高峰时间段大致为上午7:30到9:30、下午17:00到19:00,请问8月里早高峰骑行记录量(以start_time为准)高于晚高峰的有几天?
早高峰是上午7:30到9:30,需要满足start_time早于9:30和end_time晚于7:30。晚高峰同理。
(本来想法是start_time分成start_hour,start_min,也是可以的,优秀题解简洁啊,但有丢丢问题,这里改正了。)
days = []
df_mobike_week = df_mobike[df_mobike.index.dayofweek.isin([0,1,2,3,4])]
for i in range(31):
day = '2016-8-{}'.format(i+1)
morning = df_mobike_week[(df_mobike_week.index <='{} 09:30'.format(day)) &(df_mobike_week.end_time >='{} 07:30'.format(day)).values].count()[0]
afternoon = df_mobike_week[(df_mobike_week.index <='{} 19:00'.format(day)) &(df_mobike_week.end_time >='{} 17:00'.format(day)).values].count()[0]
if morning > afternoon:
days.append(day)
print('8月早高峰骑行记录量高于晚上高峰的有{}天,分别是{}'.format(len(days), days))输出:
8月早高峰骑行记录量高于晚上高峰的有5天,分别是['2016-8-4', '2016-8-27', '2016-8-28', '2016-8-29', '2016-8-30'](3)请给出在所有周五中(以start_time为准),记录条数最多的那个周五所在的日期,并在该天内分别按30分钟、2小时、6小时统计摩拜单车使用时间的均值。
找到周五(dayofweek=4),然后对天聚合求出orderid总和最大的当天。
max_friday = df_mobike[df_mobike.index.dayofweek==4]['orderid'].resample('D').count().idxmax()
print("条数最多的那个周五是",max_friday.date())输出:
条数最多的那个周五是 2016-08-26提取出当天的记录。重置索引。置新列usetime=start_time-end_time,并把单位换算成秒,即把时间间隔类型转换为float。
df_mobike_friday = df_mobike[str(max_friday.date())].copy()
df_mobike_friday = df_mobike_friday.reset_index()
df_mobike_friday['usetime'] = (df_mobike_friday.end_time-df_mobike_friday.start_time).dt.total_seconds() #转换为秒数再把start_time置为索引(上步重置索引是为了求出usetime),按照30min,2h,6h聚合,统计使用时间usetime的均值。
df_mobike_friday = df_mobike_friday.set_index('start_time',drop=False)
#print(df_mobike_friday['usetime'])
display(
df_mobike_friday['usetime'].resample('30min').mean().apply(lambda x: pd.Timedelta(seconds=int(x))).head(),
df_mobike_friday['usetime'].resample('2h').mean().apply(lambda x: pd.Timedelta(seconds=int(x))).head(),
df_mobike_friday['usetime'].resample('6h').mean().apply(lambda x: pd.Timedelta(seconds=int(x))).head()
)输出:
start_time
2016-08-26 00:00:00 00:18:56
2016-08-26 00:30:00 00:26:42
2016-08-26 01:00:00 00:13:27
2016-08-26 01:30:00 00:15:30
2016-08-26 02:00:00 00:17:17
Freq: 30T, Name: usetime, dtype: timedelta64[ns]
start_time
2016-08-26 00:00:00 00:19:57
2016-08-26 02:00:00 00:19:18
2016-08-26 04:00:00 00:13:33
2016-08-26 06:00:00 00:11:31
2016-08-26 08:00:00 00:11:35
Freq: 2H, Name: usetime, dtype: timedelta64[ns]
start_time
2016-08-26 00:00:00 00:17:47
2016-08-26 06:00:00 00:11:39
2016-08-26 12:00:00 00:16:00
2016-08-26 18:00:00 00:21:39
Freq: 6H, Name: usetime, dtype: timedelta64[ns](4)请自行搜索相关代码或调用库,计算每条记录起点到终点的球面距离。
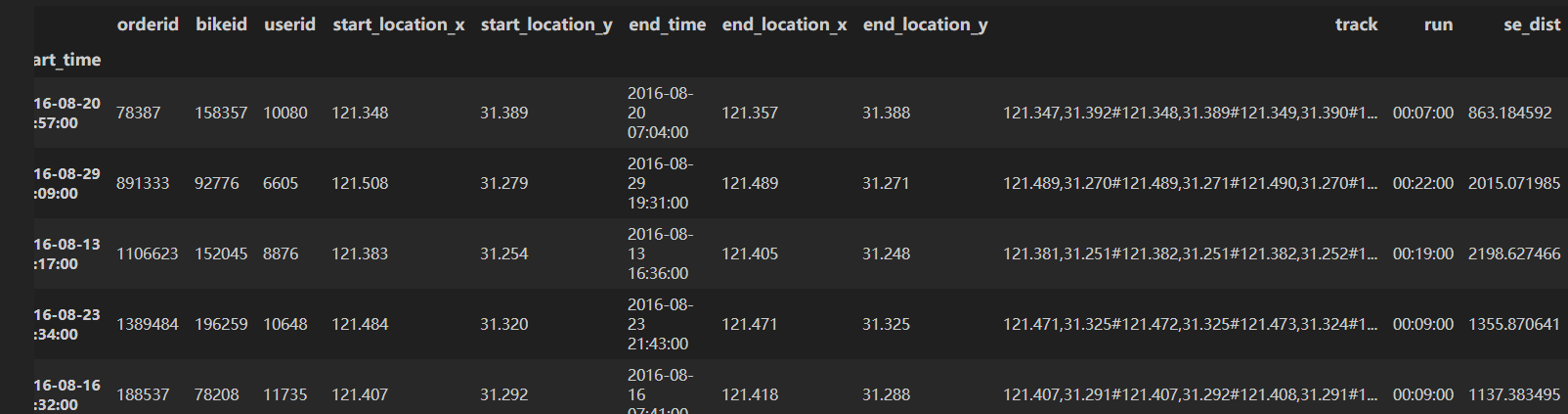
from geopy.distance import geodesic
df_mobike_dist = df_mobike.copy()
df_mobike_dist['se_dist'] = df_mobike_dist.apply(lambda x: geodesic((x.start_location_y,x.start_location_x),(x.end_location_y,x.end_location_x)).m,axis=1)
df_mobike_dist.head()输出:
(5)摩拜单车的骑行结束时间是以电子锁的记录时间为准,但有时候用户会忘记关锁,导致骑行时间出现异常。同时,正常人的骑行速度往往大致落在一个合理的区间,请结合上一问中的球面距离和骑行起始、结束时间、找出潜在的异常骑行记录。
usetime = end_time - start_time,通过se_dist/usetime得到平均速度,当速度小于一定值(这里选取0.05的分位数),可以认为是潜在的异常骑行记录。
df_mobike_dist['usetime'] = (df_mobike_dist.end_time-df_mobike_dist.index).dt.total_seconds() #转换为绝对秒数
df_mobike_dist['se_speed'] = df_mobike_dist.apply(lambda x:x.se_dist/x.usetime, axis=1)
print('mean',df_mobike_dist.se_speed.mean())
for q in [0.95,0.75,0.5,0.25,0.1,0.05,0.04,0.03,0.02,0.01,0.001]:
print(q*100,'分位数',df_mobike_dist.se_speed.quantile(q))
# 可能忘记锁车:
df_mobike_dist[df_mobike_dist.se_speed<df_mobike_dist.se_speed.quantile(0.05)].head()输出:
orderid bikeid userid start_location_x \
start_time
2016-08-29 09:21:00 270836 63136 11361 121.369
2016-08-26 22:05:00 1802934 320611 1211 121.504
2016-08-24 13:32:00 1630164 143066 11182 121.436
2016-08-27 21:52:00 1623489 151285 17526 121.478
2016-08-03 22:08:00 748550 136503 7423 121.483
start_location_y end_time end_location_x \
start_time
2016-08-29 09:21:00 31.252 2016-08-29 13:43:00 121.376
2016-08-26 22:05:00 31.305 2016-08-26 22:27:00 121.500
2016-08-24 13:32:00 31.328 2016-08-24 13:44:00 121.439
2016-08-27 21:52:00 31.289 2016-08-27 22:14:00 121.476
2016-08-03 22:08:00 31.237 2016-08-03 22:26:00 121.484
end_location_y \
start_time
2016-08-29 09:21:00 31.233
2016-08-26 22:05:00 31.308
2016-08-24 13:32:00 31.327
2016-08-27 21:52:00 31.292
2016-08-03 22:08:00 31.234
track \
start_time
2016-08-29 09:21:00 121.367,31.238#121.367,31.239#121.368,31.240#1...
2016-08-26 22:05:00 121.499,31.308#121.500,31.308#121.501,31.308#1...
2016-08-24 13:32:00 121.436,31.328#121.437,31.328#121.437,31.329#1...
2016-08-27 21:52:00 121.476,31.292#121.477,31.289#121.477,31.290#1...
2016-08-03 22:08:00 121.482,31.235#121.483,31.234#121.483,31.235#1...
se_dist usetime se_speed
start_time
2016-08-29 09:21:00 2209.621048 15720.0 0.140561
2016-08-26 22:05:00 505.608255 1320.0 0.383037
2016-08-24 13:32:00 306.300607 720.0 0.425418
2016-08-27 21:52:00 383.276389 1320.0 0.290361
2016-08-03 22:08:00 345.995048 1080.0 0.320366(6)由于路线的曲折性,起点到终点的球面距离往往不能充分反应行程的长度,请利用track列的路线坐标数据,计算估计实际骑行距离,并重新仿照上一问的方法找出可能的异常记录。
getdist把各个节点之间的距离和求出来,然后也是track_dist/usetime计算平均速度。当速度小于阈值(0.05分位数)时,认为是潜在的异常数据。
def getdist(track):
tlist = []
dist = 0
for t in track.split('#'):
for tt in t.split(','):
(tlist.append(tt))
for i in range(len(tlist)//2 - 1):
try:
dist += geodesic((tlist[i*2+1],tlist[i*2]),(tlist[i*2+3],tlist[i*2+2])).m
except ValueError:
dist += 0
return dist
df_mobike_dist['track_dist'] = df_mobike_dist.track.apply(lambda x: getdist(x))
df_mobike_dist['track_speed'] = df_mobike_dist.apply(lambda x: x.track_dist/x.usetime, axis=1)
print('mean', df_mobike_dist.track_speed.mean())
for q in [0.95,0.75,0.5,0.25,0.1,0.05,0.04,0.03,0.02,0.01,0.001]:
print(q*100,'分位数',df_mobike_dist.track_speed.quantile(q))
# 可能忘记锁车:
cut = df_mobike_dist.track_speed.quantile(0.05)
print(df_mobike_dist[df_mobike_dist.track_speed<cut])输出:
mean 4.7176424053972985
95.0 分位数 11.119561310481727
75.0 分位数 5.648633153477631
50.0 分位数 3.8691839481829473
25.0 分位数 2.6515407909180317
10.0 分位数 1.377678636142472
5.0 分位数 0.6461082249996972
4.0 分位数 0.5022487936821581
3.0 分位数 0.36700311152670406
2.0 分位数 0.2489091789770581
1.0 分位数 0.14214735328510836
0.1 分位数 0.03553589878569083
orderid bikeid userid start_location_x \
start_time
2016-08-29 09:21:00 270836 63136 11361 121.369
2016-08-31 18:15:00 1563430 384828 945 121.606
2016-08-29 07:45:00 80889 335198 12380 121.354
2016-08-16 19:56:00 1504315 78807 185 121.480
2016-08-12 22:02:00 1419609 106895 11697 121.515
... ... ... ... ...
2016-08-03 16:39:00 373681 85225 7484 121.449
2016-08-24 20:25:00 1777023 313903 13647 121.363
2016-08-24 20:13:00 1774184 103791 15364 121.530
2016-08-14 20:02:00 1459535 150325 5961 121.359
2016-08-31 19:32:00 1678292 172562 2655 121.531
start_location_y end_time end_location_x \
start_time
2016-08-29 09:21:00 31.252 2016-08-29 13:43:00 121.376
2016-08-31 18:15:00 31.110 2016-08-31 18:58:00 121.570
2016-08-29 07:45:00 31.226 2016-08-29 08:28:00 121.356
2016-08-16 19:56:00 31.311 2016-08-16 20:04:00 121.484
2016-08-12 22:02:00 31.291 2016-08-12 22:17:00 121.537
... ... ... ...
2016-08-03 16:39:00 31.269 2016-08-03 16:57:00 121.432
2016-08-24 20:25:00 31.254 2016-08-24 20:41:00 121.364
2016-08-24 20:13:00 31.324 2016-08-24 20:20:00 121.524
2016-08-14 20:02:00 31.253 2016-08-14 20:32:00 121.365
2016-08-31 19:32:00 31.284 2016-08-31 20:01:00 121.543
end_location_y \
start_time
2016-08-29 09:21:00 31.233
2016-08-31 18:15:00 31.115
2016-08-29 07:45:00 31.225
2016-08-16 19:56:00 31.305
2016-08-12 22:02:00 31.301
... ...
2016-08-03 16:39:00 31.277
2016-08-24 20:25:00 31.255
2016-08-24 20:13:00 31.328
2016-08-14 20:02:00 31.252
2016-08-31 19:32:00 31.296
track \
start_time
2016-08-29 09:21:00 121.367,31.238#121.367,31.239#121.368,31.240#1...
2016-08-31 18:15:00 121.606,31.111#121.607,31.110#121.609,31.110#1...
2016-08-29 07:45:00 121.351,31.223#121.353,31.226#121.354,31.223#1...
2016-08-16 19:56:00 121.480,31.311#121.482,31.311
2016-08-12 22:02:00 121.515,31.290#121.516,31.290
... ...
2016-08-03 16:39:00 121.448,31.270#121.449,31.269
2016-08-24 20:25:00 121.363,31.254#121.363,31.255#121.364,31.255#1...
2016-08-24 20:13:00 121.528,31.324#121.529,31.324#121.530,31.324
2016-08-14 20:02:00 121.359,31.253#121.360,31.253#121.361,31.252#1...
2016-08-31 19:32:00 121.531,31.284#121.532,31.284#121.535,31.285#1...
se_dist usetime se_speed track_dist track_speed
start_time
2016-08-29 09:21:00 2209.621048 15720.0 0.140561 6153.382509 0.391437
2016-08-31 18:15:00 3478.566745 2580.0 1.348282 432.445014 0.167614
2016-08-29 07:45:00 220.465615 2580.0 0.085452 1205.743298 0.467342
2016-08-16 19:56:00 766.519391 480.0 1.596915 190.385816 0.396637
2016-08-12 22:02:00 2369.929234 900.0 2.633255 95.214021 0.105793
... ... ... ... ... ...
2016-08-03 16:39:00 1845.992264 1080.0 1.709252 146.159845 0.135333
2016-08-24 20:25:00 146.169464 960.0 0.152260 463.165717 0.482464
2016-08-24 20:13:00 723.055998 420.0 1.721562 190.359665 0.453237
2016-08-14 20:02:00 582.165645 1800.0 0.323425 886.059173 0.492255
2016-08-31 19:32:00 1753.760319 1740.0 1.007908 738.228978 0.424270
[5118 rows x 14 columns]参考资料
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!