本文最后更新于:2020年6月27日 晚上
问题与练习
【问题一】如何使用union_categoricals方法,它的作用是什么?
- 如果要组合不一定具有相同类别的类别,union_categoricals函数将组合类似列表的类别。新类别将是合并的类别的并集。如下所示:
from pandas.api.types import union_categoricals
a = pd.Categorical(['b','c'])
b = pd.Categorical(['a','b'])
union_categoricals([a,b])输出:

- 默认情况下,生成的类别将按照在数据中显示的顺序排列。如果要对类别进行排序,可使用sort_categories=True参数。
- union_categoricals也适用于组合相同类别和顺序信息的两个分类。
- union_categoricals可以在合并分类时重新编码类别的整数代码。
【问题二】利用concat方法将两个序列纵向拼接,它的结果一定是分类变量吗?什么情况下不是?
- pd.concat对象只能是pd.Series或pd.DataFrame,所以结果是object。
- 使用union_categoricals拼接两个分类变量可得到分类变量。
【问题三】当使用groupby方法或者value_counts方法时,分类变量的统计结果和普通变量有什么区别?
- 分类变量的groupby方法/value_counts方法,统计对象是类别。
- 普通变量groupby方法/value_counts方法,统计对象是唯一值(不包含NA)。
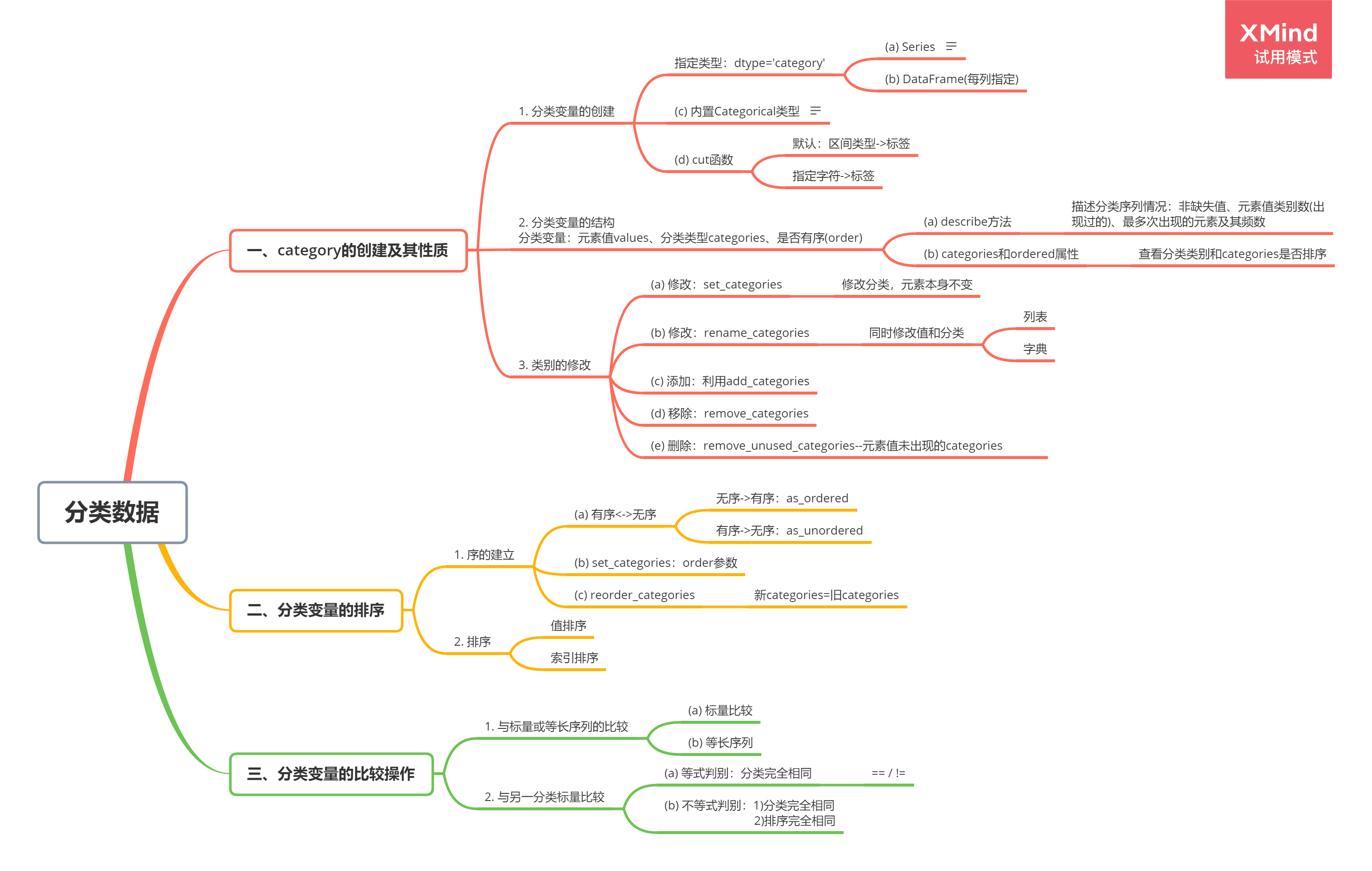
【问题四】下面的代码说明了Series创建分类变量的什么”缺陷”?如何避免?(提示使用Series的copy参数)
cat = pd.Categorical([1, 2, 3, 10], categories=[1, 2, 3, 4, 10])
s = pd.Series(cat, name="cat")
cat输出:
[1, 2, 3, 10]
Categories (5, int64): [1, 2, 3, 4, 10]s.iloc[0:2] = 10
cat输出:
[10, 10, 3, 10]
Categories (5, int64): [1, 2, 3, 4, 10]分类变量在Series改动时也被改动了。
使用copy参数避免分类变量被修改。
cat = pd.Categorical([1,2,3,10],categories=[1,2,3,4,10])
s = pd.Series(cat, name='cat', copy=True)
print(cat)
s.iloc[0:2] = 10
print(cat)输出:
【练习一】现继续使用第四章中的地震数据集,请解决以下问题:
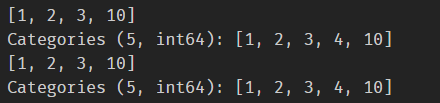
(a)现在将深度分为七个等级:[0.5,10,15,20,30,50,np.inf],请以深度Ⅰ,Ⅱ,Ⅲ,Ⅳ,Ⅴ,Ⅵ,Ⅶ为索引并按照由浅到深的顺序进行排序。
使用cut方法对列表中的深度划分,并将该列作为索引值。然后按索引排序即可。
df = pd.read_csv('data/Earthquake.csv')
df_result = df.copy()
df_result['深度'] = pd.cut(df['深度'],[0,5,10,15,20,30,50,np.inf], right=False, labels=['Ⅰ','Ⅱ','Ⅲ','Ⅳ','Ⅴ','Ⅵ','Ⅶ'])
df_result = df_result.set_index('深度').sort_index()
df_result.head()输出:
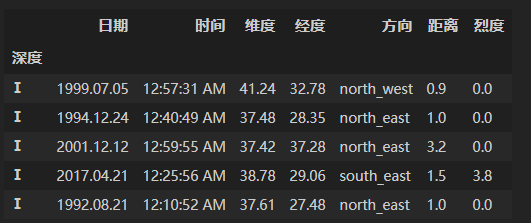
(b)在(a)的基础上,将烈度分为4个等级:[0,3,4,5,np.inf],依次对南部地区的深度和烈度等级建立多级索引排序。
跟(a)很相似,cut方法对深度,烈度进行切分,把index设为[‘深度’,‘烈度’],然后进行索引排序即可。
df['烈度'] = pd.cut(df['烈度'],[0,3,4,5,np.inf], right=False, labels=['Ⅰ','Ⅱ','Ⅲ','Ⅳ'])
df['深度'] = pd.cut(df['深度'],[0,5,10,15,20,30,50,np.inf], right=False, labels=['Ⅰ','Ⅱ','Ⅲ','Ⅳ','Ⅴ','Ⅵ','Ⅶ'])
df_ds = df.set_index(['深度','烈度'])
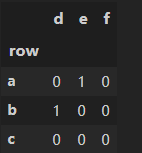
df_ds.sort_index()【练习二】 对于分类变量而言,调用第4章中的变形函数会出现一个BUG(目前的版本下还未修复):例如对于crosstab函数,按照官方文档的说法,即使没有出现的变量也会在变形后的汇总结果中出现,但事实上并不是这样,比如下面的例子就缺少了原本应该出现的行’c’和列’f’。基于这一问题,请尝试设计my_crosstab函数,在功能上能够返回正确的结果。
因为Categories中肯定包含出现的变量。所以将第一个参数作为index,第二个参数作为columns,建立一个DataFrame,然后把出现的变量组合起来,对应位置填入1即可。
foo = pd.Categorical(['b','a'], categories=['a', 'b', 'c'])
bar = pd.Categorical(['d', 'e'], categories=['d', 'e', 'f'])
import numpy
def my_crosstab(a, b):
s1 = pd.Series(list(foo.categories), name='row')
s2 = list(bar.categories)
df = pd.DataFrame(np.zeros((len(s1), len(s2)),int),index=s1, columns=s2)
index_1 = list(foo)
index_2 = list(bar)
for loc in zip(index_1, index_2):
df.loc[loc] = 1
return df
my_crosstab(foo, bar)输出:
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!